Abstract
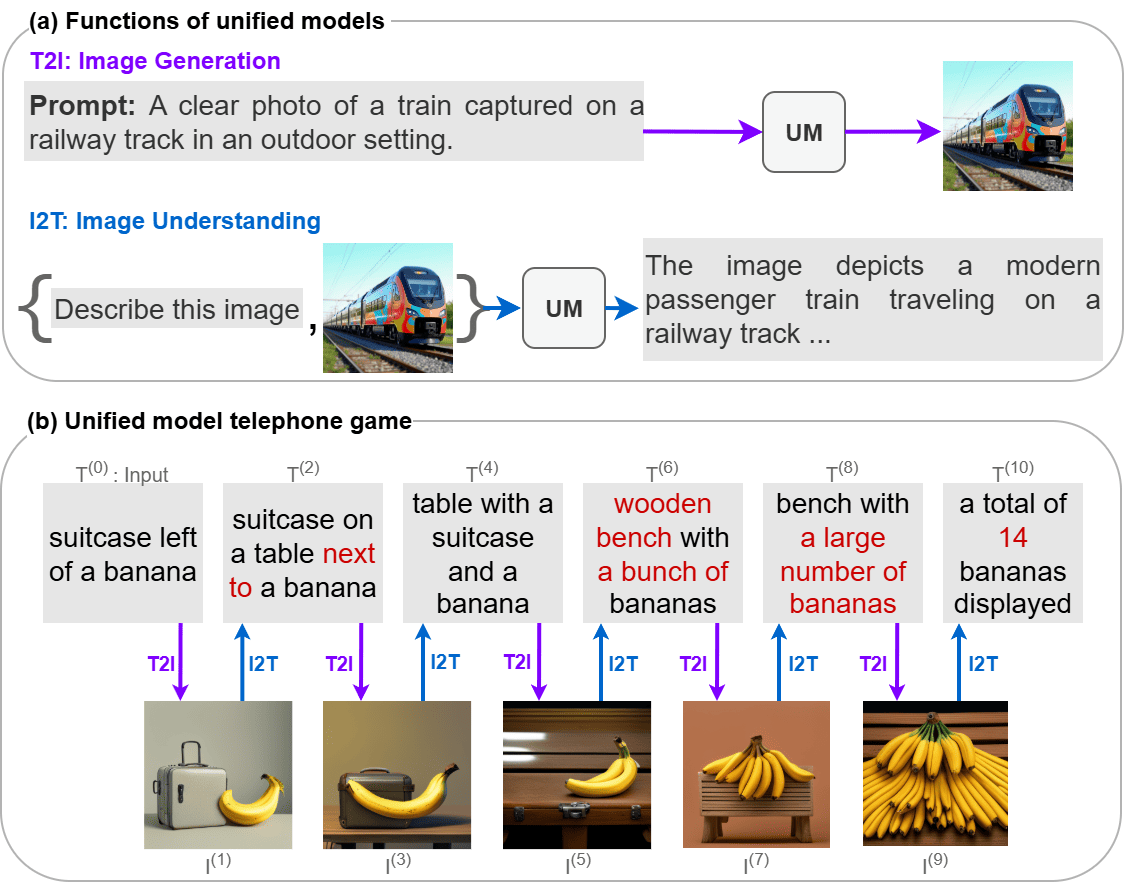
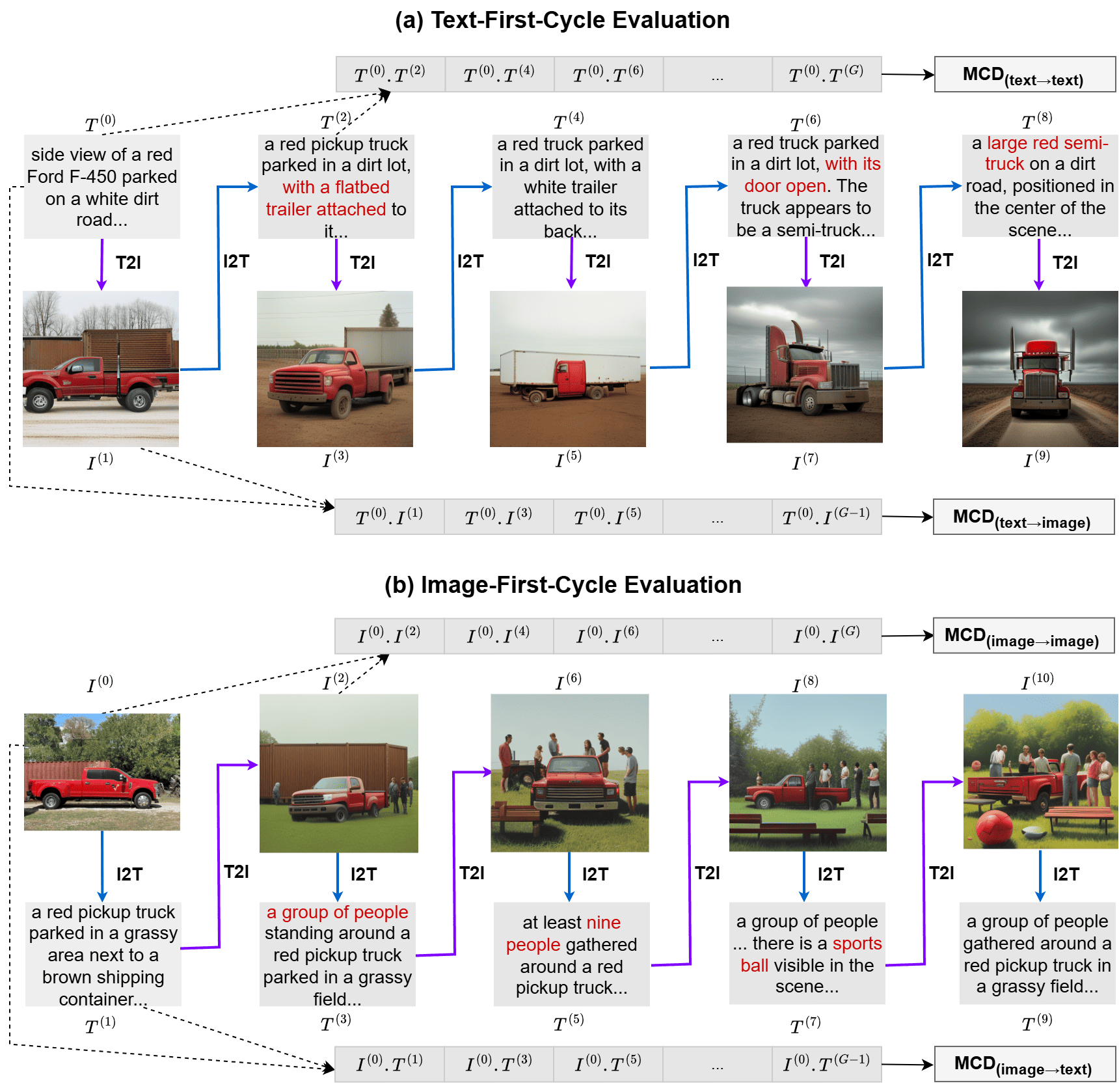
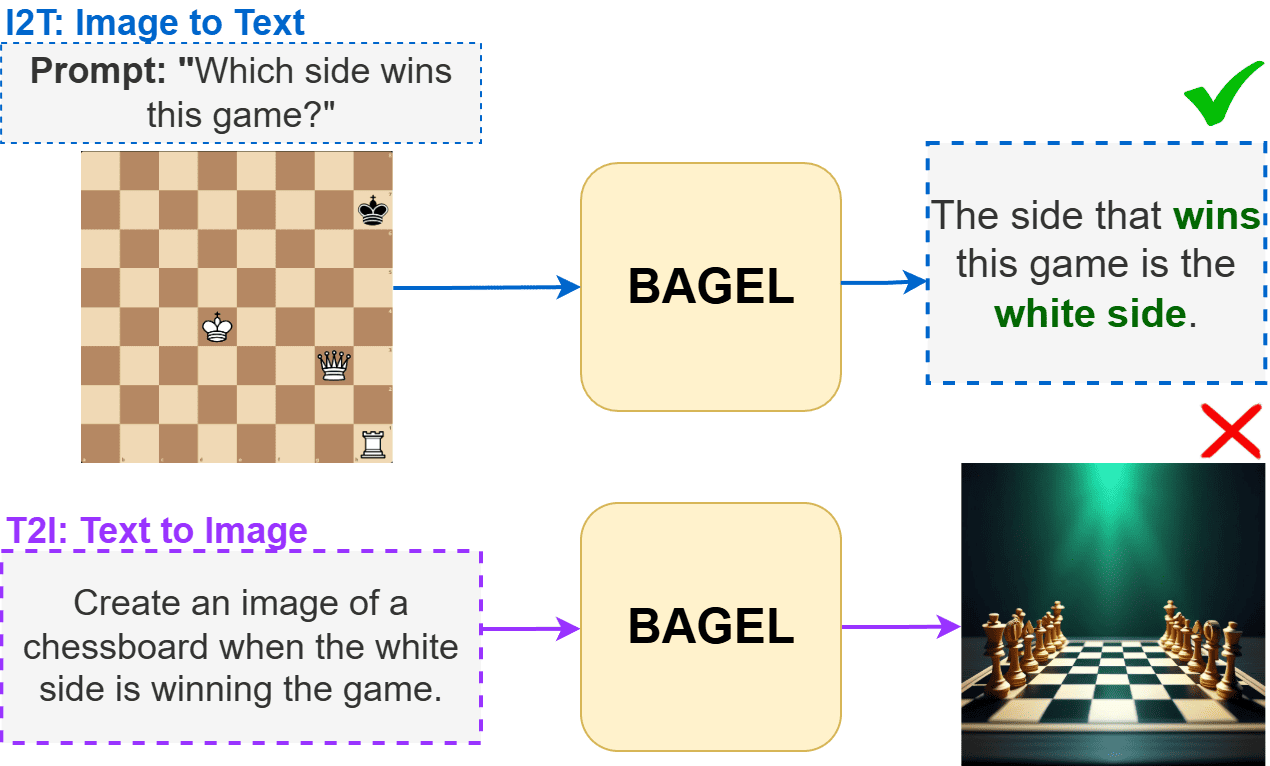
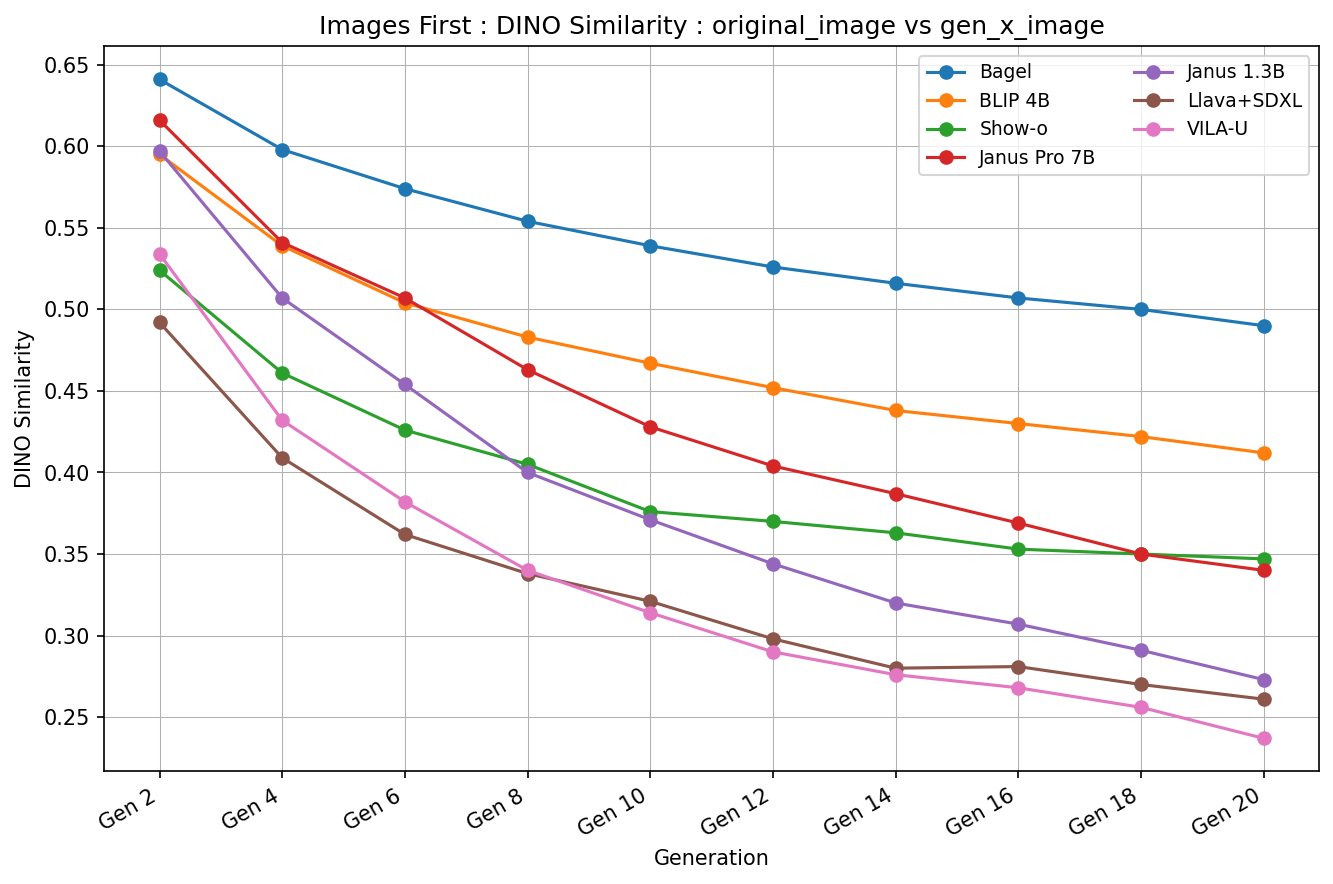
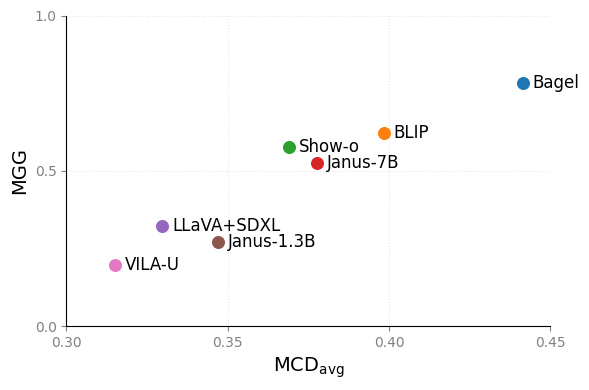
Employing a single, unified model (UM) for both visual understanding (image-to-text: I2T) and visual generation (text-to-image: T2I) has opened a new direction in Visual Language Model (VLM) research. While UMs can also support broader unimodal tasks (e.g., text-to-text, image-to-image), we focus on the core cross-modal pair T2I and I2T. Existing evaluation benchmarks consider these capabilities in isolation: FID and GenEval for T2I, and benchmarks such as MME, MMBench for I2T. These isolated single-pass metrics do not reveal cross-consistency: whether a model that “understands” a concept can also “render” it, nor whether semantic meaning is preserved when cycling between image and text modalities. To address this, we introduce the Semantic Drift Protocol (SDP) for Unified Models, a cyclic evaluation protocol that alternates I2T and T2I over multiple generations to quantify semantic drift. We propose two metrics: (i) Mean Cumulative Drift (MCD), an embedding-based measure of overall semantic drift; and (ii) Multi-Generation GenEval (MGG), an object-level compliance score extending GenEval. To assess generalization beyond COCO dataset, which is widely used in training; we create a new benchmark Nocaps+Docci400, sampled from NoCaps and DOCCI and evaluated on seven recent models. SDP reveals substantial variation in cross-modal stability: some models like BAGEL maintain semantic meaning over many alternations, whereas others like VILA-U drift quickly despite strong single-pass scores. Our results highlight SDP as a necessary complement to standard I2T and T2I evaluations.